
发布日期: 2025-04-09 19:30:32
在日常办公或学习中,频繁复制粘贴内容时,你是否经历过这样的困扰:刚复制的文字...

发布日期: 2025-03-27 13:24:17
在编程学习与日常工具开发中,图形用户界面(GUI)的设计往往是提升用户体验的重要...

发布日期: 2025-04-22 17:50:21
在互联网业务高速发展的当下,CDN缓存刷新效率直接影响用户体验与业务稳定性。传统...

发布日期: 2025-04-23 14:24:02
在中文学习和教学领域,汉字拼音转换工具已成为不可或缺的实用助手。这类工具通过...

发布日期: 2025-04-23 14:59:50
键盘声夹杂着咖啡机的嗡鸣,凌晨三点的书房里,一位开发者正反复调试着网页动画参...

发布日期: 2025-04-24 18:14:07
在信息爆炸的数字化时代,外语学习者常面临资源过载的困境。据某语言学习平台202...

发布日期: 2025-04-25 10:45:41
在现代工作与学习中,计算器始终是不可或缺的实用工具。随着技术发展,传统实体计...

发布日期: 2025-03-27 13:42:01
在日常办公或学习中,PDF文件因其兼容性强、格式稳定的特点,成为文档传输的主流格...

发布日期: 2025-04-16 12:53:14
在日常工作中,许多人面临信息重复传递的困扰——同一份通知需手动转发到多个群组...

发布日期: 2025-03-30 15:07:24
在日常工作与学习中,电子设备中堆积的文件常常让人陷入混乱。文档、图片、视频、...

发布日期: 2025-03-29 10:01:29
在互联网技术快速迭代的背景下,自动化工具的应用场景愈发广泛。其中,结合验证码...

发布日期: 2025-04-24 18:46:09
信息爆炸时代催生了海量电子文档的管理需求。某跨国企业的法务部门曾面临典型困境...

发布日期: 2025-04-12 13:15:41
在在线教育快速发展的背景下,学习路径推荐算法逐渐成为提升用户学习效率的核心技...

发布日期: 2025-04-07 17:04:27
化学元素周期表的掌握是科学教育的基础,但传统学习工具常受限于单一语言,对非母...

发布日期: 2025-04-22 18:54:31
全球信息流动加速的背景下,语言障碍成为制约跨文化协作的首要难题。基于神经网络...

发布日期: 2025-04-09 17:47:05
在数字化办公场景中,权限管理始终是困扰企业IT部门的难题。某跨国能源企业曾因权...

发布日期: 2025-03-31 14:50:04
在日常工作或学习中,截屏功能的使用频率远超想象。无论是保存重要资料、记录操作...

发布日期: 2025-04-07 09:27:33
互联网时代,即时响应成为用户服务的核心诉求。一套高效的在线聊天机器人自动回复...

发布日期: 2025-04-23 19:16:33
在自然语言处理技术快速发展的今天,基于NLTK工具包搭建的简易聊天机器人成为许多开...

发布日期: 2025-04-17 14:50:18
在信息爆炸的时代,微信已成为个人与企业的核心沟通工具。每天面对海量消息,如何...

发布日期: 2025-04-14 17:50:44
在语言学习过程中,词汇积累是绕不开的基础环节。一款名为 Tkinter背单词测验程序 的...
发布日期: 2025-04-14 16:49:00
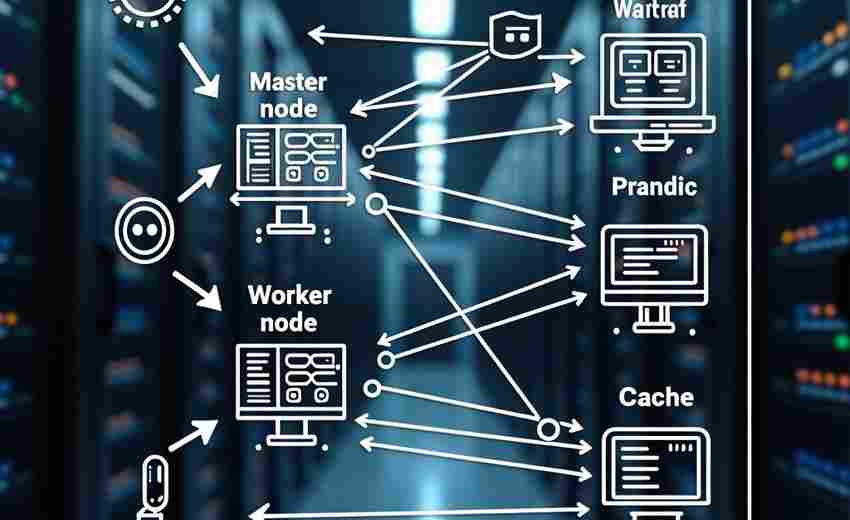
在深度学习领域,工具框架的选择往往决定着研究者的思维路径。当研究人员在2017年前...
发布日期: 2025-04-25 15:16:46
在编程学习过程中,将抽象数学概念转化为直观图形是一种有效的方法。Python自带的...

发布日期: 2025-04-12 13:40:30
现代技术环境中,聊天机器人逐渐成为企业与用户互动的高效工具。近期市场上出现了...

发布日期: 2025-03-22 09:10:01
在编程学习或日常开发中,进制转换是高频需求。二进制、八进制、十进制和十六进制...

发布日期: 2025-04-03 15:27:40
清晨地铁里,指尖划动手机屏幕的年轻人正在复习昨日标注的三十个生词;午休时间,...

发布日期: 2025-03-26 15:52:04
深灰色办公桌前,设计师小林对着屏幕抓头发——客户要求的「复古莫兰迪色调」方案...
发布日期: 2025-03-22 11:05:21
日常办公与学习中,一款操作流畅、界面简洁的计算器应用能够显著提升效率。基于...

发布日期: 2025-04-04 19:12:39
当代生活节奏加快,日程管理成为刚需。微信生态内悄然流行起一类新型工具——倒计...

发布日期: 2025-03-27 10:33:23
语言学习者常被生词记忆困扰。纸质笔记本记录效率低,电子文档整理耗时耗力。针对...

发布日期: 2025-04-05 17:18:34
在分布式系统与云端服务普及的当下,运维团队对异常事件的响应速度直接影响业务连...

发布日期: 2025-04-22 16:14:11
运维团队最怕深夜被电话惊醒,但服务器宕机从不挑时间。传统邮件、短信报警存在延...

发布日期: 2025-03-22 10:58:20
语言学习中,生词积累与复习效率直接影响学习效果。一款专注于 生词管理+科学复习...

发布日期: 2025-03-28 10:30:28
在视障教育领域,一款名为"BrailleTracker"的软件逐渐进入大众视野。这款工具通过数据化...

发布日期: 2025-04-08 17:40:55
背单词是语言学习中绕不过的关卡,但传统方法常让人陷入"背了忘、忘了背"的循环。...

发布日期: 2025-03-21 14:03:04
在数字身份安全威胁频发的当下,密码强度评估工具正成为企业安全架构的重要组件。...

发布日期: 2025-04-16 12:31:45
外语学习者的手机里总少不了一款单词记忆软件。纸质笔记本时代,泛黄的书页和散落...
发布日期: 2025-04-13 10:15:55
机器学习模型的训练过程常被形容为"黑箱",开发者往往需要反复调试代码、核对日志...

发布日期: 2025-03-29 12:41:30
外语学习进入移动化时代,纸质单词本逐渐被智能工具取代。一款高效的单词本背诵工...

发布日期: 2025-04-18 19:43:26
在日常办公或学习场景中,文件管理常成为效率瓶颈。尤其当硬盘积累大量文档、图片...

发布日期: 2025-04-04 14:11:37
在编程学习与开发场景中,轻量化的代码工具正逐渐成为主流。近期测试的某款在线编...

发布日期: 2025-04-12 15:24:02
办公桌或学习区域堆积的便签纸,常因信息混杂导致效率下降。颜色分类管理法通过视...

发布日期: 2025-04-08 11:11:34
语言学习中,词汇积累是绕不开的基础环节。面对海量生词,传统背诵方法常因缺乏系...

发布日期: 2025-04-12 13:29:59
微信作为国民级即时通讯工具,其自动化应用场景逐渐受到开发者关注。基于Python的...

发布日期: 2025-04-15 17:26:44
在英语阅读和写作中,超过25个单词的复杂句式常成为理解障碍。传统语法书提供的模...
发布日期: 2025-04-14 16:12:56
碎片化时代,专注力成为稀缺资源。一款名为 StudyTrack Pro 的仪表盘工具,正试图通过「...

发布日期: 2025-04-01 09:46:03
在日常办公与学习场景中,PDF文档的灵活处理已成为高频需求。面对动辄数百页的合同...

发布日期: 2025-04-01 15:50:12
对于日常学习或工作中常涉及单位换算的人群而言,传统计算器往往显得笨拙。输入公...

发布日期: 2025-04-11 17:56:31
纸质单词本曾是语言学习者的标配,但随着数字工具的普及,电子单词本与闪卡类应用...

发布日期: 2025-04-02 12:30:45
现代人学习语言时总会遇到一个难题:背过的单词隔天就忘。市面上的单词本记忆软件...

发布日期: 2025-04-17 12:17:32
翻开一本厚重的单词书,密密麻麻的字母在眼前跳动,记忆仿佛被按下了删除键。这种...

发布日期: 2025-04-14 16:41:50
碎片化时代对学习效率提出更高要求,全球在线教育市场规模预计在2025年突破3500亿美...

发布日期: 2025-04-23 14:09:46
纸质单词本在语言学习领域存在了半个多世纪。1983年牛津大学出版社的调查显示,83...

发布日期: 2025-04-01 14:35:11
在语言学习过程中,拼写错误如同顽固的"拦路虎",反复消耗学习者的时间与耐心。一...

发布日期: 2025-04-13 11:49:11
外语学习者的桌面常堆满各国教材,泛黄的纸页间夹杂着荧光笔标记与潦草笔记。当遇...

发布日期: 2025-04-09 10:19:23
工业机器人关节磨损趋势预测工具近年来成为智能制造领域的热门技术方向。作为工业...

发布日期: 2025-04-10 14:53:03
深夜十一点半,手机突然震动着弹出提示:"您的'量子纠缠'卡片即将到期,友情提醒:...

发布日期: 2025-04-03 15:09:34
互联网时代的信息以秒速更迭,微博热搜榜作为全民话题风向标,时刻牵动着媒体从业...
