
发布日期: 2025-03-30 14:39:01
在数据驱动的时代,网页爬虫已成为获取公开信息的核心工具。但对于非专业开发者而...
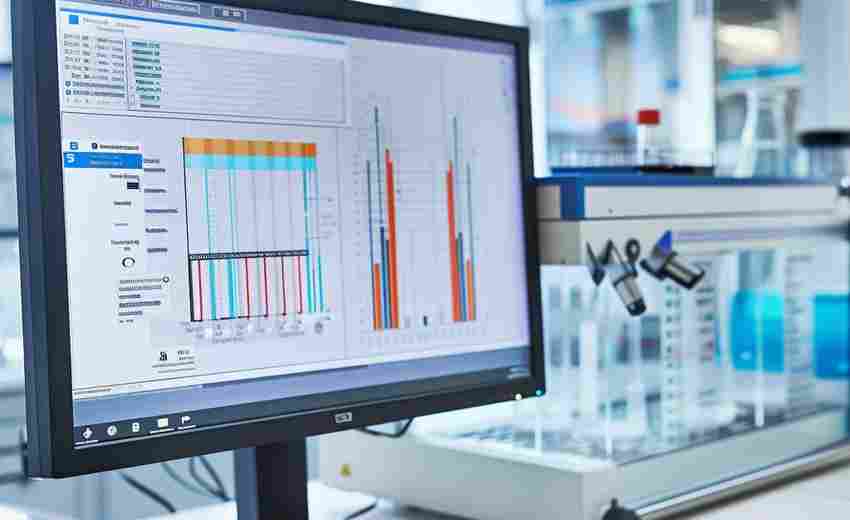
发布日期: 2025-03-22 09:53:27
在实验科学领域,数据的准确记录与高效分析是研究成败的关键。传统的人工记录与计...

发布日期: 2025-03-31 11:02:05
在全球化网络部署场景中,设备厂商常面临同一型号硬件适配多地区环境的挑战。以某...

发布日期: 2025-03-23 10:29:34
某科技公司安全团队在2022年的内网渗透测试中,意外发现攻击者使用新型分布式端口扫...

发布日期: 2025-03-29 13:42:01
网络课程二维码教学资质自动验证工具诞生于在线教育快速发展的背景之下。随着各大...

发布日期: 2025-03-22 09:45:24
在互联网信息爆炸的当下,快速定位目标网站的核心信息成为许多从业者的刚需。无论...

发布日期: 2025-03-25 14:55:29
最近在排查服务器网络异常时,发现市面上的监控工具要么功能冗余,要么配置复杂。...

发布日期: 2025-04-03 18:43:32
在数据采集需求日益增长的背景下,一款名为WebExtractor的轻量级工具在开发者社区引发...
发布日期: 2025-03-31 17:33:59
数字化浪潮推动企业数据存储需求呈指数级增长,传统存储管理方式逐渐暴露出响应滞...

发布日期: 2025-03-22 10:16:01
窗外的天气从晴转阴,电脑屏幕上的壁纸却依然停留在三个月前下载的雪景图。这种场...

发布日期: 2025-03-23 12:26:30
在电商平台批量采集商品图、为论文收集实验样本、给自媒体账号储备封面素材——这...
发布日期: 2025-03-29 16:36:36
互联网基础设施的复杂程度与日俱增,某开源社区近期发布的TrafficShaper Pro V3.2版本引发...

发布日期: 2025-04-03 10:59:32
网络端口状态检测是渗透测试的基础环节。三年前参与某次内网安全演练时,我亲历了...

发布日期: 2025-03-26 19:05:21
在网络安全领域,多因素认证(MFA)曾被视为账户安全的终极防线。当某跨国企业的安...

发布日期: 2025-03-30 14:21:18
在复杂的网络环境中,QoS(服务质量)策略的配置与生效状态直接影响业务传输的稳定...

发布日期: 2025-03-24 09:07:34
在企业IT基础设施中,每天约有37%的运维故障源于网络依赖失效。传统人工巡检方式已...

发布日期: 2025-03-21 11:53:18
当前网络环境中,视频平台的VIP内容解析工具正悄然改变着用户的观影方式。这类工具...

发布日期: 2025-04-02 15:18:03
在嵌入式开发与教学实验领域,一台手掌大小的虚拟执行设备往往比笨重的物理设备更...

发布日期: 2025-03-25 15:24:01
夜深人静,某企业安全工程师王工盯着屏幕上跳动的扫描进度条。他正在使用TCP端口扫...

发布日期: 2025-03-26 17:06:55
在复杂的网络环境中,ARP表作为二层通信的核心枢纽,承载着IP地址与MAC地址的动态映...

发布日期: 2025-04-02 11:05:18
在信息泄露频发的数字时代,个人隐私文件需要更可靠的保护方案。基于AES(高级加密...

发布日期: 2025-04-01 14:46:06
网络爬虫技术在论坛数据采集中扮演着重要角色。本文以Python语言为例,介绍如何构建...

发布日期: 2025-04-03 15:38:23
在互联网数据采集领域,递归式网络爬虫因其自动遍历特性备受开发者青睐。这类工具...

发布日期: 2025-03-24 09:08:40
互联网时代,海量数据隐藏在网页背后,如何高效获取目标信息成为刚需。网页爬虫技...

发布日期: 2025-04-01 10:50:13
在数字化业务场景中,服务器每天产生的日志数据量以TB级递增。如何从海量日志中快...

发布日期: 2025-03-23 10:43:45
网络卡顿、视频会议掉线、文件传输中断……这些问题背后往往存在同一个隐形杀手—...
发布日期: 2025-03-29 16:29:25
航空出行日益普及,航班延误却成为困扰旅客与航司的痛点。如何快速获取准确的延误...

发布日期: 2025-04-02 10:11:52
对于动漫爱好者来说,追番最头疼的问题莫过于错过更新。传统的手动刷新不仅效率低...

发布日期: 2025-03-28 14:18:40
在数字化场景日益复杂的今天,网络稳定性已成为企业运营和个人用户体验的核心命脉...

发布日期: 2025-04-06 17:28:29
机房里几十台服务器同时运转,后台数据吞吐量每秒高达数亿字节。某天凌晨两点,某...

发布日期: 2025-03-28 16:29:50
在互联网信息爆炸的时代,数据采集效率直接影响着企业决策和业务迭代速度。面对动...

发布日期: 2025-03-21 12:02:42
对于需要频繁处理工程图纸的设计师或施工方来说,传统CAD软件存在启动慢、操作复杂...

发布日期: 2025-04-02 09:04:14
在数据处理需求爆炸式增长的当下,网络爬虫已成为获取信息的必备工具。基于Python开...

发布日期: 2025-04-02 12:44:36
在大数据时代,获取网络信息的效率直接影响着决策质量。一款支持关键词过滤的简易...

发布日期: 2025-04-05 13:52:01
在网络安全威胁日益复杂的今天,密码管理已成为企业及个人防护体系中最基础的环节...
发布日期: 2025-03-27 19:31:08
全球网络环境存在天然的地域差异,即便同一国家的不同区域,网站访问速度也可能产...

发布日期: 2025-04-06 18:14:43
在数字化场景中,应用程序的网络连接行为直接影响系统安全性与运行效率。后台程序...

发布日期: 2025-04-01 16:00:42
在数字信息爆炸的时代,一份合同、一组设计图或是一段家庭视频的意外丢失,都可能...

发布日期: 2025-04-03 13:29:47
窗外的雨点敲打着玻璃,李然盯着电脑屏幕弹出的"硬盘损坏"提示,手指微微发凉。这...

发布日期: 2025-03-22 11:10:49
在内容运营与数据分析领域,微信公众号作为中文内容生态的核心平台,其文章标题的...

发布日期: 2025-03-30 12:34:21
互联网从业者常面临服务器响应速度的波动问题。某跨国团队曾因未及时检测到亚太节...

发布日期: 2025-04-02 13:24:01
在计算机网络运维中,延迟检测是衡量链路质量的核心指标之一。基于ICMP协议开发的...

发布日期: 2025-03-31 13:35:17
按下视频播放键的瞬间,屏幕突然卡成马赛克画质;游戏团战关键时刻人物集体掉线;...

发布日期: 2025-03-26 18:54:26
在互联网应用中,代理服务器的重要性无需赘述。但市面上的验证工具要么操作繁琐,...

发布日期: 2025-04-02 11:01:34
在数字化高度渗透的日常中,网络连接中断如同突然断电般令人抓狂。无论是远程会议...

发布日期: 2025-03-24 11:05:46
在网络运维与开发场景中,抓包分析是定位问题的核心手段。传统工具如Wireshark虽然功...

发布日期: 2025-04-01 11:04:24
社交网络时代,每个人的好友列表都像一张错综复杂的蛛网。好友关系网络拓扑可视化...

发布日期: 2025-03-29 11:23:12
在信息碎片化的时代,视频平台成为许多人获取内容的主要渠道。YouTube作为全球头部平...

发布日期: 2025-03-31 10:05:04
互联网数据呈指数级增长,如何从海量信息中快速抓取特定格式的文件,成为许多用户...

发布日期: 2025-04-02 10:47:34
当代互联网每天产生约2.5万亿字节数据,手工收集信息早已不现实。以Python生态为基础...

发布日期: 2025-03-25 11:20:06
清晨拉开窗帘,阳光是否刺眼?深夜加班回家,是否需要带伞?现代人对于天气信息的...

发布日期: 2025-03-28 18:27:01
许多小说爱好者都遇到过类似困扰:网页端阅读体验差,分章节下载耗时费力,保存后...

发布日期: 2025-03-31 12:23:50
凌晨三点的机房警报声突然响起,运维工程师老张揉着惺忪睡眼冲进监控室。墙面上那...

发布日期: 2025-04-06 18:57:35
在网络流量爆炸式增长的今天,企业服务器每秒可能接收数万条数据请求,其中隐藏着...

发布日期: 2025-03-24 13:12:02
在互联网信息爆炸的今天,定向获取特定网站的数据成为许多人的刚需。一款针对单一...

发布日期: 2025-03-27 09:07:00
微博热搜榜作为中文互联网实时舆情的风向标,每天吸引数亿用户关注。如何高效获取...

发布日期: 2025-04-04 10:35:04
按下测速按钮的瞬间,数字开始跳动。下载速度从0.1MB/s急速攀升到12.5MB/s,上传速度则...

发布日期: 2025-04-06 16:19:55
互联网平台运营过程中产生的海量日志数据,往往蕴含着关键业务信息。某电商平台技...

发布日期: 2025-03-26 09:49:02
在信息爆炸的数字化时代,语音转文字工具逐渐成为职场、学习场景中的刚需。这类工...

发布日期: 2025-03-27 11:19:43
在网络通信中,重复数据包通常被视为"冗余噪音"。它们可能由设备故障、配置错误或...
")