
发布日期: 2025-04-02 14:31:43
旅游旺季出行最头疼的莫过于门票价格波动。上海迪士尼平日499元的门票,节假日可能...

发布日期: 2025-03-29 17:58:30
许多人都有过这样的经历:新电脑开机仅需8秒,使用半年后进度条卡在登录界面转圈,...

发布日期: 2025-04-04 16:32:24
多维度网站可用性监控与告警系统作为现代企业数字化运营的核心工具,正在改变传统...

发布日期: 2025-03-28 19:52:43
在数字化办公场景中,电脑卡顿、程序崩溃、数据丢失等问题频繁困扰职场人。如何快...
发布日期: 2025-04-05 15:42:23
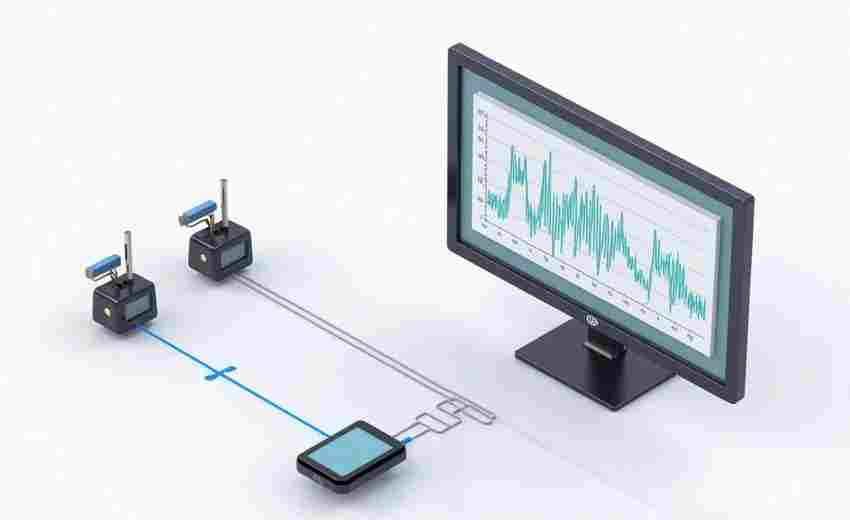
在数字化基础设施规模指数级增长的今天,服务器、网络设备、应用程序每天产生的日...
发布日期: 2025-03-21 11:31:36
在软件开发与系统运维领域,环境变量配置长期被视为"必要但麻烦"的基础工作。不同...

发布日期: 2025-03-30 17:40:54
在企业级IT运维或日常开发场景中,系统日志的爆炸式增长与磁盘空间告警往往成为高...

发布日期: 2025-03-25 10:40:52
服务器机房里闪烁的指示灯背后,每天产生着数以GB计的系统日志。某金融科技企业的...

发布日期: 2025-04-04 09:31:09
凌晨三点的企业机房,某台服务器的支付网关进程突然崩溃,值班工程师的手机未收到...

发布日期: 2025-04-05 12:47:44
高温警报在设备启动阶段频繁触发,产线被迫暂停——某半导体工厂的工程师面对突发...
发布日期: 2025-03-31 11:37:41
专业摄影师和摄影爱好者每年都会积累数万张原始图像文件,传统的文件夹分类方式已...

发布日期: 2025-03-24 12:19:09
在局域网办公场景中,两台工作站间的文件同步需求普遍存在却常被忽视。某科技团队...
发布日期: 2025-04-09 17:18:19
在软件开发与系统测试环节,真实数据模拟始终是验证功能完整性的关键步骤。某新型...
发布日期: 2025-03-27 14:46:16
随着城市绿植覆盖率提升至42%,市民园艺活动参与率同比增长67%,传统纸质登记模式已...

发布日期: 2025-03-28 17:01:51
在分布式架构与云计算普及的当下,服务器集群规模呈指数级增长。某电商平台曾因一...

发布日期: 2025-04-03 13:01:17
日志文件作为系统运行的核心记录载体,其分析效率直接影响运维响应速度。传统单线...

发布日期: 2025-03-23 12:35:12
现代职场人常陷入多重任务漩涡:会议纪要写到一半被电话打断,客户需求邮件在收件...

发布日期: 2025-03-28 11:45:34
机房的红色警报灯突然闪烁,值班工程师的手机弹出三条告警信息:核心交换机端口丢...

发布日期: 2025-04-01 11:18:37
在文学研究、内容创作甚至司法鉴定领域,辨别不同作者的写作风格一直是项复杂任务...

发布日期: 2025-03-25 14:55:29
最近在排查服务器网络异常时,发现市面上的监控工具要么功能冗余,要么配置复杂。...

发布日期: 2025-03-24 11:50:19
工作间隙查看手机时,发现下午的会议还剩半小时;赶稿过程中突然意识到截稿时间逼...

发布日期: 2025-03-23 09:18:56
互联网服务的高可用性已成为企业生存的底线要求。某科技公司曾因服务中断15分钟损...

发布日期: 2025-03-30 13:38:32
传统商务场景中,名片交换后的信息处理始终是个痛点。某外贸公司市场总监李明曾算...

发布日期: 2025-03-31 16:36:24
在分布式系统或跨区域网络中,服务器时间的一致性直接影响日志分析、事务处理等核...

发布日期: 2025-04-03 11:31:47
在数据交换需求频繁的办公场景中,FTP协议仍是跨平台传输的可靠选择。Python生态圈提...

发布日期: 2025-03-22 13:28:01
清晨六点的纽约交易所电子屏尚未亮起,某私募基金的量化交易员已经收到预警邮件。...

发布日期: 2025-03-22 11:47:57
电脑用久了难免卡顿?明明没开几个程序,硬盘灯却闪个不停。许多用户习惯通过清理...

发布日期: 2025-04-01 11:57:45
厨房抽屉里翻出过期三年的感冒药,卧室柜底发现变质的消炎药片,这类场景在多数家...

发布日期: 2025-04-06 15:08:37
在线考试系统的开发中,单选题作为基础题型,其功能实现直接影响系统的可用性。利...

发布日期: 2025-04-10 11:05:11
在Linux或Windows系统中,符号链接(Symbolic Link)如同文件系统的快捷方式,极大提升了资...

发布日期: 2025-03-24 09:53:56
深夜的机房只有服务器指示灯在闪烁,磁盘阵列的嗡鸣声突然变得急促。运维人员手机...

发布日期: 2025-03-21 11:25:41
任何接入互联网的计算机都可能面临输入信息窃取风险。硬件层面存在USB接口键盘记录...

发布日期: 2025-03-31 19:47:50
跨系统协作时,文件编码问题常引发数据乱码或程序崩溃。某款名为CodeGuard的桌面工具...
发布日期: 2025-03-30 17:33:44
电脑卡顿时频繁点击任务管理器的用户,服务器机房内盯着命令行滚动的运维工程师,...
发布日期: 2025-03-25 15:48:55
在工业控制与物联网场景中,实时监控系统的开发效率直接影响项目进度。PySimpleGUI作...

发布日期: 2025-04-06 17:46:19
Windows电脑突然弹出蓝屏警告,小刘的手指悬在键盘上迟迟无法敲下重启指令。这个在科...

发布日期: 2025-04-03 17:28:43
企业通讯录管理一直是内部协作的痛点。纸质通讯录易丢失,Excel表格版本混乱,专业...

发布日期: 2025-03-31 19:15:35
窗外的梧桐叶在风中沙沙作响,办公桌上的电脑屏幕亮着五颜六色的K线图。张先生滑动...

发布日期: 2025-04-07 18:08:27
对于许多电脑用户而言,系统开机速度始终是个痛点。尤其当安装的软件逐渐增多,任...

发布日期: 2025-04-04 10:21:02
许多团队在组织活动时都面临过投票效率低下的困扰。纸质表格统计耗时长,微信群接...

发布日期: 2025-03-29 15:18:00
基础工具组:账户操作三板斧 Linux 系统管理员最常接触的 useradd、usermod、userdel 命令构...

发布日期: 2025-04-10 10:08:01
办公桌上堆满文件令人心烦意乱,电子设备里的重复文件同样让人头疼。某科技团队研...

发布日期: 2025-03-22 09:55:46
婚礼策划中最易引发混乱的环节莫过于宾客座位安排。传统手工制表常因数据混乱导致...

发布日期: 2025-03-25 09:29:40
在物流行业高速发展的当下,园区内车辆的调度效率直接影响着整体运营成本与服务质...

发布日期: 2025-03-28 10:05:53
在数字内容创作领域,字体呈现效果直接影响着作品的视觉传达力。当设计师在排版软...
发布日期: 2025-03-31 15:22:01
传统服务器运维工作中,命令行操作占据着绝对主导地位。某跨国企业的数据中心曾做...
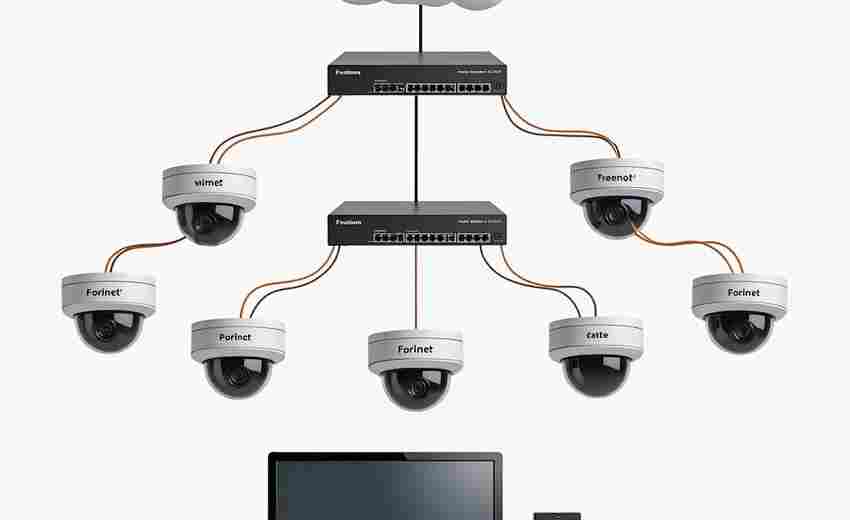
发布日期: 2025-04-07 10:53:04
在企业信息化建设进程中,共享文件夹已成为部门协作的重要载体。某医疗器械公司曾...

发布日期: 2025-03-31 14:03:40
在数据爆炸式增长的今天,外接硬盘、U盘、NAS等存储设备已成为日常办公的刚需。但设...

发布日期: 2025-04-04 11:29:43
装修采购的复杂程度常被低估。据行业数据显示,75%的业主在装修过程中遭遇过材料漏...
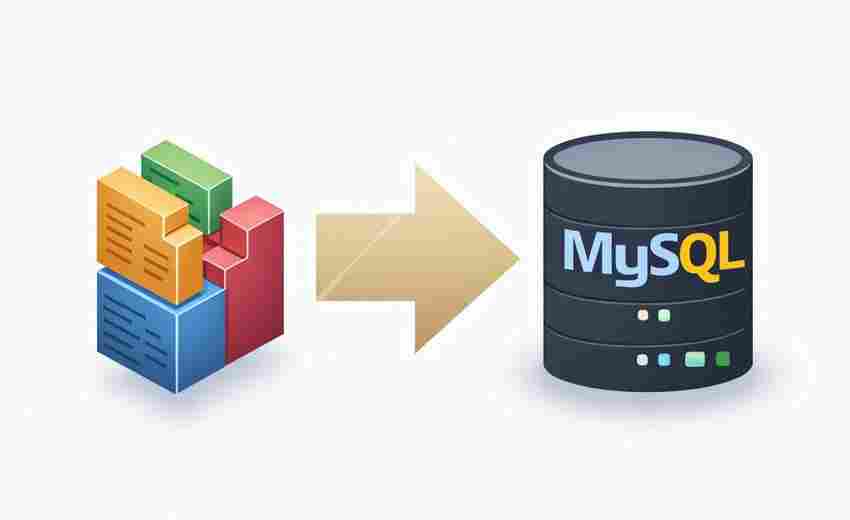
发布日期: 2025-03-29 16:18:51
数据库表结构同步在分布式系统开发、数据迁移或灾备场景中属于高频操作。传统人工...
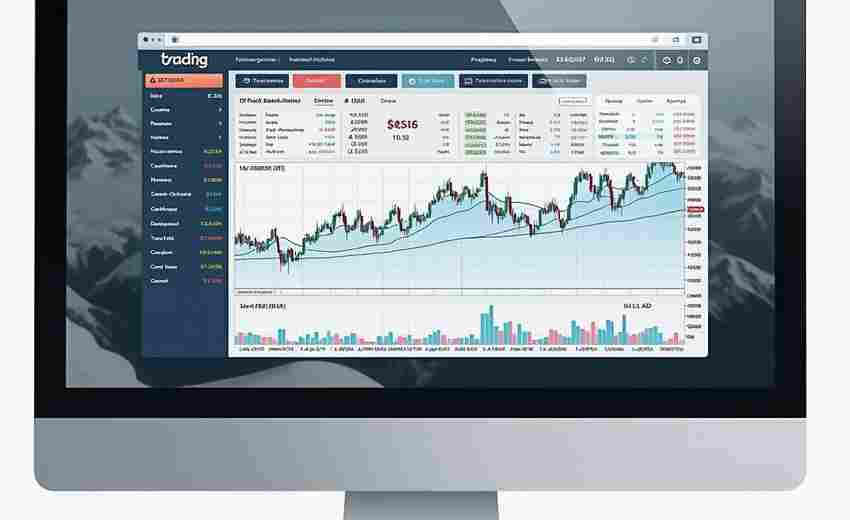
发布日期: 2025-03-30 16:33:01
电脑屏幕频繁切换股票页面的困扰,大多数股民都经历过。随着盯盘工具不断迭代,多...

发布日期: 2025-03-24 10:37:26
办公族的电脑用了半年后突然卡顿,游戏玩家的设备莫名发热,设计师的硬盘空间总是...

发布日期: 2025-04-01 11:47:07
清晨八点的办公室,某互联网公司的技术总监李航习惯性打开监控面板。一组红色预警...

发布日期: 2025-03-30 13:20:45
在全球化的商业场景中,货币代码的准确性直接影响交易效率和数据处理能力。为满足...

发布日期: 2025-03-31 10:12:01
在频繁需要跨服务器传输数据的开发场景中,Python内置的ftplib模块为工程师提供了快速...
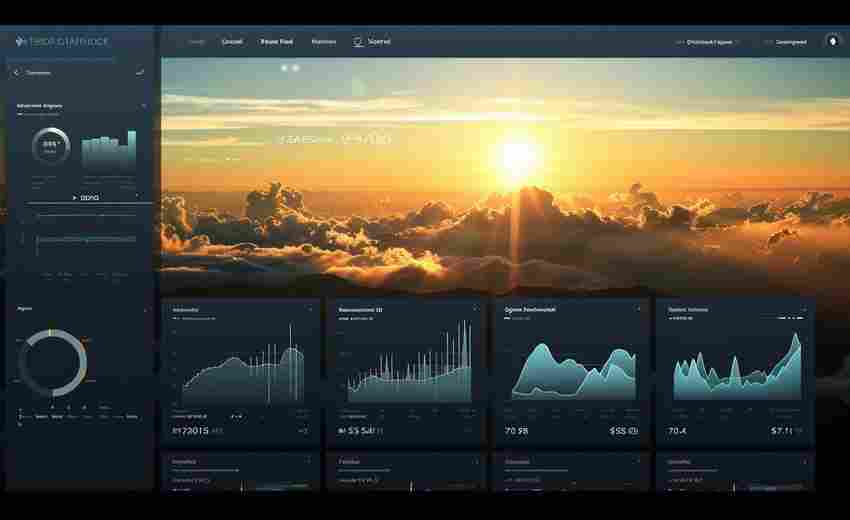
发布日期: 2025-04-05 15:35:15
对于开发者而言,系统资源监控是日常工作中不可或缺的实用需求。Python生态中,PyS...

发布日期: 2025-04-04 19:44:40
现代办公场景中,外接硬盘、U盘、NAS等存储设备已成为数据流转的核心载体。某互联网...

发布日期: 2025-04-01 09:21:01
Windows系统盘突然飘红时,屏幕前的你是否有过对着"磁盘清理"工具发呆的经历?那些带...

发布日期: 2025-04-01 18:55:22
在距地球400公里的轨道上,封闭的金属舱室承载着人类探索宇宙的雄心。这里每立方厘...

发布日期: 2025-04-01 10:10:38
在分布式架构主导的互联网环境中,服务可用性直接决定业务存亡。当人工巡检无法应...
