
发布日期: 2025-03-30 14:56:52
窗口标签页挤满任务栏、服务器IP地址混淆、频繁输入密码手忙脚乱——每个运维工程...
发布日期: 2025-04-04 17:25:30
窗外雨滴敲打键盘的深夜里,程序员们总会怀念那个没有臃肿框架的时代。Flask作为P...

发布日期: 2025-04-03 18:43:32
在数据采集需求日益增长的背景下,一款名为WebExtractor的轻量级工具在开发者社区引发...

发布日期: 2025-04-03 15:27:40
清晨地铁里,指尖划动手机屏幕的年轻人正在复习昨日标注的三十个生词;午休时间,...

发布日期: 2025-03-27 15:21:46
在局域网环境中,消息广播工具常被用于快速传递信息,尤其适合小型团队协作或临时...
发布日期: 2025-03-30 16:33:01
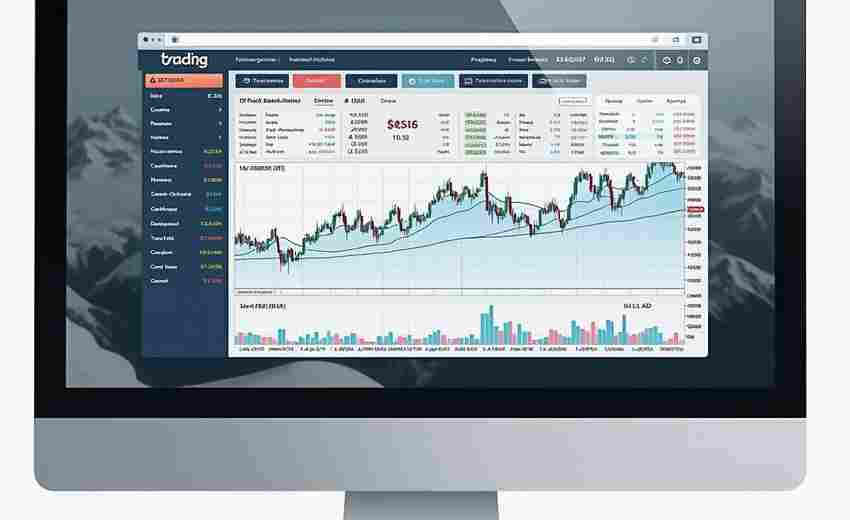
电脑屏幕频繁切换股票页面的困扰,大多数股民都经历过。随着盯盘工具不断迭代,多...

发布日期: 2025-04-02 10:44:00
在数字工具泛滥的当下,一款没有复杂界面、不依赖网络环境的命令行待办事项工具,...

发布日期: 2025-03-31 13:35:17
按下视频播放键的瞬间,屏幕突然卡成马赛克画质;游戏团战关键时刻人物集体掉线;...

发布日期: 2025-04-06 18:46:52
在局域网协作或远程服务器管理中,文件传输效率直接影响工作进度。传统U盘拷贝、社...

发布日期: 2025-03-22 09:31:33
日常工作中最让人头疼的场景莫过于处理多台设备间的文件同步问题。同事小李上周就...

发布日期: 2025-04-04 10:21:02
许多团队在组织活动时都面临过投票效率低下的困扰。纸质表格统计耗时长,微信群接...

发布日期: 2025-04-01 12:51:01
在快节奏的商业场景中,数据采集效率往往决定着决策质量。某互联网公司市场部员工...
发布日期: 2025-03-21 09:17:36
对于需要频繁截图的用户而言,系统自带的截图工具往往存在功能局限。一款名为Qui...

发布日期: 2025-04-09 13:39:46
在现代网络传输场景中,FTP协议依然承担着基础文件传输的重要角色。对于习惯使用终...

发布日期: 2025-04-05 18:47:42
窗台上斜放的咖啡杯冒着热气,工程师老张的草稿纸已写满三页算式。他习惯性摸出手...

发布日期: 2025-03-24 11:18:36
办公桌前的键盘声此起彼伏,闪烁的光标前总在上演相似的场景:刚复制好的地址被新...

发布日期: 2025-04-03 12:18:23
数字时代的信息管理常陷入两难:功能齐全的笔记软件需要适应复杂操作逻辑,云存储...

发布日期: 2025-04-09 16:53:37
网络运维工作中,端口扫描是摸清资产底数的常规操作。传统单线程扫描器面对C段地址...

发布日期: 2025-04-12 16:03:43
现代人的电子设备常被各类任务挤占。视频会议需要同步记录要点,网课教程得配合实...

发布日期: 2025-04-12 19:45:02
在云服务主导的互联网时代,某款基于本地存储的博客系统悄然在开发者社区流行。这...

发布日期: 2025-03-25 17:35:49
日常工作中处理PDF文件时,常会遇到需要精准提取特定页面或整合多份资料的情况。一...

发布日期: 2025-04-06 16:42:02
在日常工作中,邮件沟通占据重要地位。但发件人往往面临两大困扰:对方是否及时查...

发布日期: 2025-04-01 17:44:09
在众多数据库管理工具中,SQLite以其轻量化和零配置的特点脱颖而出。对于开发者和运...

发布日期: 2025-03-23 09:58:06
在数字信息交互频繁的当下,文本编码问题常成为跨平台协作的隐形障碍。例如从Win...

发布日期: 2025-03-24 10:05:46
日常开发过程中,项目代码量的增长往往超出预期。面对数千行混杂着业务逻辑与注释...

发布日期: 2025-04-08 12:26:30
打开手机应用商店搜索"日历",上百款应用让人眼花缭乱。其中有个绿色图标的程序下...

发布日期: 2025-04-02 13:41:51
语言障碍在全球化场景中愈发凸显。一款支持多语种API调用的翻译工具,正在成为跨语...

发布日期: 2025-04-06 11:04:43
迷宫生成与求解一直是算法教学中经典且有趣的案例。近期,一款开源的简易迷宫工具...

发布日期: 2025-04-10 18:36:01
在数字安全领域,验证码系统承担着人机识别的重要使命。一款名为CaptchaTool的开源工...
发布日期: 2025-03-27 16:18:49
端口扫描工具作为网络安全领域的"听诊器",能够快速探查目标主机的服务开放状态。...

发布日期: 2025-03-31 19:22:46
纸质资料电子化的浪潮下,PDF格式文档早已渗透各个领域。某次学术会议上,某研究团...

发布日期: 2025-04-05 14:59:39
金融市场瞬息万变,投资者需要快速捕捉价格波动信号。基于API数据接口的股票价格监...

发布日期: 2025-04-04 15:35:22
打开浏览器搜索"网络测速",首页跳出的工具总是自带广告弹窗,测速结果还会被运营...

发布日期: 2025-04-05 11:33:01
在电子邮件通信场景中,阅读回执功能始终存在争议。发送者希望确认信息触达效果,...

发布日期: 2025-04-08 15:39:46
在办公园区封闭网络环境下,如何实现安全便捷的内部沟通?笔者通过三周时间开发完...

发布日期: 2025-04-09 13:04:10
午后的办公室充斥着键盘敲击声,技术主管李明第三次在记事本里翻找昨天配置的阿里...

发布日期: 2025-03-26 12:54:02
本地开发场景中,SQLite因其零配置、单文件存储的特性广受欢迎。面对上百兆的数据库...

发布日期: 2025-04-06 11:55:18
在数字阅读逐渐取代纸质书籍的当下,电子书格式的兼容性问题成为困扰读者的主要障...

发布日期: 2025-04-02 18:51:02
在数字音频设备泛滥的当下,一款不占内存、功能纯粹的音乐播放器反而成了稀缺品。...

发布日期: 2025-04-14 18:18:03
互联网时代的信息爆炸让许多人陷入焦虑。每天面对海量资讯,如何高效筛选有价值的...

发布日期: 2025-04-08 13:34:13
数字阅读时代,电子书格式转换已成为日常需求。一款名为BookClean的免费工具近期在开...

发布日期: 2025-04-10 12:37:48
数字阅读时代,电子书已成为许多人获取知识的首选载体。不同设备、不同平台对文件...

发布日期: 2025-03-30 17:05:09
在日常办公场景中,数据工程师经常需要处理来自各部门的Excel原始数据。这些文件普...

发布日期: 2025-03-31 10:12:01
在频繁需要跨服务器传输数据的开发场景中,Python内置的ftplib模块为工程师提供了快速...

发布日期: 2025-03-23 09:49:23
对于开发者或运维人员而言,实时掌握服务器运行状态是保障业务稳定的基础。传统监...

发布日期: 2025-03-22 12:38:42
在数据驱动的开发场景中,数据库查询效率直接影响工作流质量。一款名为 QueryCli 的开...

发布日期: 2025-04-08 18:59:19
打开电脑写文档时,总有人对着凌乱的格式皱眉头。调整标题字号、对齐段落、插入代...

发布日期: 2025-03-24 09:32:02
手机存储空间总是不够用?市面上的音乐软件动辄占用几个G内存,附带一堆用不上的社...

发布日期: 2025-03-29 16:47:14
在数据驱动的互联网时代,网络爬虫已成为企业获取公开信息的重要技术手段。爬虫运...

发布日期: 2025-03-25 18:57:37
在分布式系统管理和远程运维场景中,命令行工具的远程控制能力至关重要。一种基于...

发布日期: 2025-03-28 14:32:56
屏幕录制已成为现代人记录操作流程、分享创意内容的重要方式。在众多工具中, 简易...
发布日期: 2025-04-11 12:02:10
在项目管理领域,效率与责任划分直接影响最终成果。某款以看板模式为核心的协作工...

发布日期: 2025-04-01 15:53:46
在数据驱动的场景中,快速定位并提取信息是许多开发者和分析师的核心需求。SQL Te...

发布日期: 2025-03-25 17:25:02
对于股票投资者而言,实时掌握价格波动是决策的关键。一款功能直观、数据精准的股...

发布日期: 2025-03-28 10:34:18
网络爬虫技术为数据采集提供了便利,表格数据抓取作为其中高频需求,已成为市场研...

发布日期: 2025-04-14 10:35:29
通过TCP协议的三次握手机制,端口扫描工具能够快速识别目标主机的网络服务开放情况...

发布日期: 2025-03-23 10:47:19
在线简易备忘录:用分类标签重塑效率管理 现代人生活节奏快,待办事项常如潮水般涌...

发布日期: 2025-03-22 09:28:01
在信息爆炸的数字化时代,高效获取有效资讯逐渐成为刚需。基于RSS技术的新闻聚合工...

发布日期: 2025-03-24 14:00:46
纸质书籍的厚重感逐渐被电子墨水取代时,一款轻量化的阅读工具成为刚需。电子书阅...

发布日期: 2025-04-15 12:14:53
(空一行) 实时通信功能已成为现代Web应用的标配需求。Flask作为轻量级Python框架,配...
")