
发布日期: 2025-03-22 09:33:58
在数字设计领域,颜色精准度直接决定作品的视觉呈现效果。无论是网页设计、UI界面...

发布日期: 2025-04-09 09:43:44
在工业设计、3D打印及数字化建模领域,STL格式因其广泛兼容性成为三维模型传输的标...

发布日期: 2025-03-21 14:06:56
桌面便签贴纸工具作为效率提升的隐形助手,正在被越来越多职场人士和创意群体接受...

发布日期: 2025-03-27 14:42:44
在咖啡店点单台前,顾客用手机扫过菜单二维码;快递站货架上,分拣员用扫码枪识别...

发布日期: 2025-04-03 18:47:06
窗外蝉鸣渐歇,书桌上草稿纸堆得老高。刚列完月度开支表的小张对着手机计算器叹了...

发布日期: 2025-04-07 13:29:48
日常办公与资料整理场景中,常会遇到分散的文档需要整合的情况。比如市场部需要将...
发布日期: 2025-04-06 15:58:28
打开终端窗口,输入一行代码就能完成复杂算式、单位换算甚至汇率转换——对于程序...

发布日期: 2025-04-06 10:32:30
午后阳光斜照在设计工作室的显示屏上,设计师王蕊的鼠标悬停在网页渐变色块的交接...

发布日期: 2025-03-23 10:09:25
办公室的打印机突然罢工,同事急需一份合同文档,对方手机型号老旧无法使用常规传...

发布日期: 2025-04-18 13:36:02
午后的阳光斜照在显示屏右下角,一组像素风格的复古时钟突然跳转为极简线条表盘。...

发布日期: 2025-04-09 16:32:03
现代计算器早已突破传统数学工具的局限,成为日常生活不可或缺的助手。具备四则运...

发布日期: 2025-03-27 14:28:30
现代人手机里至少装着三个日程管理软件,但真正好用的工具往往藏在细节里。近期测...

发布日期: 2025-04-11 17:31:32
在服务器机房昏暗的灯光下,运维工程师老张盯着屏幕上滚动的日志洪流,突然捕捉到...

发布日期: 2025-03-26 18:58:13
现代人面对繁杂事务时,纸质便签与零散备忘录的局限性愈发明显。一款支持CSV导出的...

发布日期: 2025-03-23 14:12:01
每次整理工作周报时,总要在十多个窗口间反复切换截图。直到上个月发现某款轻量级...
发布日期: 2025-03-24 11:02:30
数字时代下,海量图片处理已成为摄影师、设计师、电商运营等群体的日常刚需。面对...

发布日期: 2025-04-02 15:35:50
午后的阳光斜照在咖啡杯边缘,行政助理小林第3次修改会议安排时,电脑突然弹出提醒...

发布日期: 2025-04-04 16:00:00
在数字文件管理领域,批量压缩工具已成为企业办公和日常使用的刚需。市面主流的压...

发布日期: 2025-04-05 18:51:06
在数据处理领域,编码转换始终是开发者的高频需求。Base64与ASCII码对照表生成器作为...

发布日期: 2025-04-18 14:29:53
在互联网信息爆炸的时代,网页链接的稳定性直接影响用户体验与业务连续性。传统单...

发布日期: 2025-04-04 09:08:59
在日常办公与数据处理中,CSV与Excel格式的转换需求频繁出现。例如,数据分析师常需...

发布日期: 2025-03-25 11:30:46
教育工作者常面临成绩管理的多重挑战。传统的手工记录方式不仅耗费时间,数据核对...

发布日期: 2025-03-21 11:57:01
一、工具定位与核心功能 桌面宠物动画工具是一款专为提升用户桌面趣味性设计的轻量...

发布日期: 2025-04-19 17:20:38
日常办公场景中,经常遇到需要集中处理大量文件打印任务的情况。某企业文员在季度...

发布日期: 2025-03-29 12:41:30
外语学习进入移动化时代,纸质单词本逐渐被智能工具取代。一款高效的单词本背诵工...

发布日期: 2025-03-20 16:13:38
在数据处理和传输过程中,Base64编码作为二进制转文本的标准方案,被广泛应用于邮件...

发布日期: 2025-03-27 09:32:52
打开一份来自海外的数据报表时,屏幕突然跳出的方块符号让工作陷入停滞;在解析历...

发布日期: 2025-03-26 10:31:48
在日常文件管理中,重复性的命名工作常让人疲惫不堪。某款基于正则表达式与序号生...

发布日期: 2025-04-13 13:00:40
压缩文件已成为数字生活中不可或缺的存储形式。面对各类ZIP格式文档,一款得心应手...

发布日期: 2025-04-05 17:32:47
当某外贸公司的技术主管张林第一次收到日本客户的邮件附件时,他面对乱码的CSV文件...

发布日期: 2025-04-11 13:49:28
在日常文档处理工作中,各类文本文件的编码格式差异常常带来意想不到的麻烦。当面...
发布日期: 2025-04-16 12:28:09
在会议管理场景中,预约提醒环节常因人工操作产生疏漏。某款会议预约提醒短信自动...

发布日期: 2025-03-22 11:24:22
在软件开发过程中,代码行数统计是衡量项目规模、评估工作量的常见需求。无论是个...

发布日期: 2025-03-23 09:20:02
机房警报声突然响起时,运维人员的第一反应往往是抓起键盘输入ping命令。这个诞生于...

发布日期: 2025-04-13 17:26:26
在数字化办公场景中,文件编码问题常成为跨平台协作的隐形障碍。一份文档从Window...

发布日期: 2025-04-13 15:13:51
在日常办公与资料管理中,用户常面临海量文件内容检索的需求。传统搜索工具依赖文...

发布日期: 2025-04-13 15:10:24
日常工作中,纸质文档的页码标记习惯被延续到电子文件领域。对于合同、标书、学术...

发布日期: 2025-04-05 10:46:47
厨房里飘着葱油香气,主妇正揉搓着沾满面粉的双手,对着台面上的黑色方盒喊出:...

发布日期: 2025-03-29 10:04:55
在数字办公场景中,PPT文件转存为独立图片的需求量逐年攀升。某款新近开发的自动化...

发布日期: 2025-04-14 18:55:59
在短视频与动态内容主导的社交时代,动画GIF因其轻量化和循环播放的特性,成为表情...

发布日期: 2025-04-15 16:51:01
办公桌上堆满不同格式的文档时,文件名中杂乱的扩展名总让人头疼。某互联网公司的...

发布日期: 2025-03-29 16:08:08
市面上各类文本编辑器琳琅满目,但真正符合基础办公需求的工具往往隐匿在复杂功能...

发布日期: 2025-04-19 14:25:59
场景痛点 凌晨两点,某电商平台的服务器集群突发磁盘告警。运维团队需在200台机器上...

发布日期: 2025-04-16 12:10:11
在快节奏的现代办公场景中,邮件依然是商务沟通的重要载体。面对频繁的客户联络、...

发布日期: 2025-03-24 14:00:46
纸质书籍的厚重感逐渐被电子墨水取代时,一款轻量化的阅读工具成为刚需。电子书阅...

发布日期: 2025-04-13 12:17:46
程序员小张盯着屏幕上两份相似度99%的配置文件,额头渗出细密的汗珠。凌晨三点的办...

发布日期: 2025-04-12 15:20:26
在日常数据处理工作中,频繁面对CSV文件与数据库之间的转换需求是许多开发者、数据...

发布日期: 2025-04-07 12:29:14
当设计师将200张产品图上传至电商平台时,突然发现系统仅支持WebP格式;自媒体小编在...

发布日期: 2025-04-06 12:45:02
在数字化办公场景中,企业级邮件发送工具正逐步替代传统邮件客户端。基于SMTP协议的...

发布日期: 2025-03-27 18:09:18
在碎片化学习与多任务处理场景下,某款国产视频播放器近期引发市场关注。这款支持...

发布日期: 2025-03-26 10:28:14
几何图形与色彩的结合,构成了现代视觉设计的底层逻辑。Adobe Illustrator、CorelDRAW等专...

发布日期: 2025-03-30 10:04:35
【深度解析】支持SSML的TSS脚本编辑器:语音交互开发者的新利器 在语音交互技术快速...

发布日期: 2025-04-09 13:04:10
午后的办公室充斥着键盘敲击声,技术主管李明第三次在记事本里翻找昨天配置的阿里...

发布日期: 2025-03-23 10:22:09
电脑屏幕前的设计师常常需要从一张图片、一段视频甚至一个网页中快速提取颜色编码...

发布日期: 2025-04-05 17:25:40
当代内容创作者面临一个矛盾:既需要专注内容质量,又得花时间与排版工具纠缠。一...

发布日期: 2025-04-19 18:21:02
在分布式系统架构大行其道的今天,研发团队每天需要处理数以千计的配置文件。这些...

发布日期: 2025-03-30 11:33:53
打开手机应用商店搜索"记账软件",超过90%的产品都在强调界面美观或智能统计,却鲜...

发布日期: 2025-03-22 13:44:23
在数据处理与文件交换场景中,企业常面临文件格式转换的重复性工作。某技术团队开...
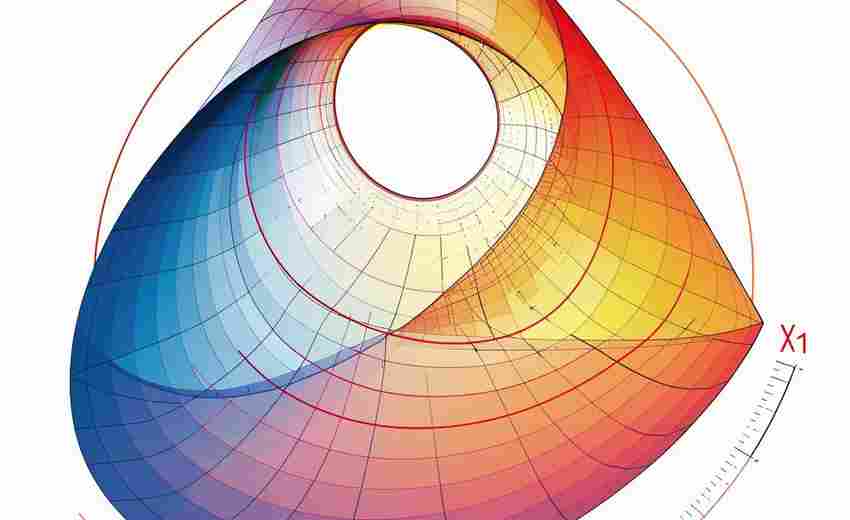
发布日期: 2025-04-01 12:40:31
在数学教学和科研领域,可视化工具始终是理解抽象概念的重要桥梁。某款支持动态参...

发布日期: 2025-04-11 16:59:22
在日常开发或运维工作中,日志文件的编码格式混乱常让人头疼。不同系统、不同应用...
