
发布日期: 2025-03-23 09:53:44
在日常学术研究及商务办公场景中,PDF文档的版权保护需求日益增长。某款自主研发的...

发布日期: 2025-03-29 19:55:54
在科研机构负责数据管理的老张最近遇到了头疼事——每周需要从合作单位的FTP服务器...

发布日期: 2025-04-03 11:46:04
学术引用情感关联性检测工具近年来逐渐成为科研领域的热门辅助手段。该工具通过分...
发布日期: 2025-03-22 13:47:24
在科研实验与工业质检场景中,数据异常值常如“暗礁”般潜藏于海量结果中。传统人...

发布日期: 2025-03-29 15:39:36
在科研领域,选题方向往往决定着研究价值与成果传播力。一款基于多维度数据聚合的...

发布日期: 2025-03-22 13:40:01
各类机构在开展市场调研或学术研究时,常面临多选题数据的处理难题。传统统计工具...

发布日期: 2025-04-10 14:13:56
学术会议日程信息的高效获取一直是研究人员面临的现实难题。面对分散在不同平台、...
发布日期: 2025-03-25 13:26:27
在科研与工业领域,实验样品的规范化管理直接影响研究效率与数据可靠性。传统人工...

发布日期: 2025-04-04 09:12:43
在学术写作中,论文格式的规范性常被视为细节问题,却直接影响评审专家的第一印象...

发布日期: 2025-03-26 17:17:35
学术文献管理中的PDF元数据处理难题长期困扰研究者群体。面对海量文献资源,如何快...

发布日期: 2025-03-31 16:43:52
学术研究领域对创新性的要求日益严格,传统查重系统仅能识别文字重复的局限性逐渐...

发布日期: 2025-04-04 10:42:31
全球科研合作与跨国工程项目的激增,使得单位转换成为日常工作中不可忽视的痛点。...
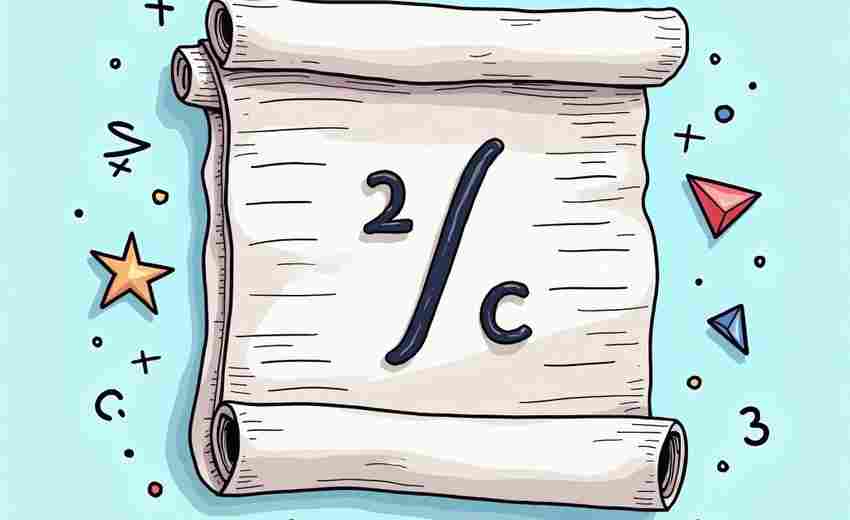
发布日期: 2025-03-31 16:08:11
在学术写作与技术文档领域,数学公式的呈现质量直接影响专业内容的可信度。传统排...

发布日期: 2025-04-12 10:06:47
科研工作者对期刊影响因子的依赖早已成为行业共识。这个数值不仅是衡量期刊学术影...

发布日期: 2025-04-07 19:34:00
数学爱好者、科研工作者或是普通学生,或许都曾好奇过圆周率(π)小数点后的奥秘...

发布日期: 2025-03-24 13:45:22
在短视频创作、影视剪辑或科研分析领域,帧级精度往往直接影响作品质量。传统截取...

发布日期: 2025-03-21 10:43:07
实验室的台灯下,凌晨三点的咖啡早已凉透,机械重复的Excel操作让研二学生陈浩的手...

发布日期: 2025-04-04 16:21:37
在跨学科研究日益频繁的科研环境中,学术论文插图格式的规范化需求持续增长。据统...

发布日期: 2025-03-26 17:35:22
国内科研机构近年普遍面临设备采购预算紧张的难题。某高校实验室负责人透露:"去年...
发布日期: 2025-04-10 18:58:30
科研数据处理中,异常值的识别与处理直接影响研究结论的可靠性。传统人工筛查不仅...

发布日期: 2025-04-11 17:13:39
在科研实验室的日常运作中,安全考试是保障人员操作规范性的核心环节。许多实验室...

发布日期: 2025-04-05 13:09:01
随着学术研究规范化要求的提升,科研工作者对论文原创性的保障需求日益增长。一款...

发布日期: 2025-03-26 09:41:54
在实验室工作台上,研究员常被杂乱的数据表格与手绘曲线图困扰。一款专为科研场景...
发布日期: 2025-04-06 12:16:41
学术写作中,数学公式的呈现一直是让人头疼的问题。传统文档编辑器对LaTeX的支持有...

发布日期: 2025-04-05 16:10:53
在科研工作中,期刊影响因子始终是学者选择投稿平台的重要参考指标。传统查询方式...

发布日期: 2025-03-23 11:10:26
在学术研究领域,及时获取最新期刊文献已成为科研工作者的刚性需求。据统计,全球...

发布日期: 2025-03-21 12:01:14
在信息爆炸的学术研究领域,文献处理效率直接影响科研进度。某技术团队近期推出的...

发布日期: 2025-04-09 19:44:49
在科研工作者日常工作中,期刊影响因子始终是衡量学术成果质量的重要参考指标。当...

发布日期: 2025-04-04 18:12:01
科研文献关键词共现网络分析工具作为知识图谱构建的重要载体,正在成为学术研究领...

发布日期: 2025-04-09 09:25:55
现代学术研究过程中,文献管理始终是困扰研究者的重要课题。据统计,全球科研人员...

发布日期: 2025-04-10 11:33:35
在科研实验中,数据对比是验证假设、发现规律的关键环节。传统人工比对方式耗时费...

发布日期: 2025-04-09 16:14:18
在学术研究与内容创作领域,查重工具的普及极大提升了文本原创性审查的效率。传统...

发布日期: 2025-04-07 13:11:58
学术期刊编辑部的办公桌上,堆积如山的审稿意见PDF文件往往占据大量空间。传统人工...
发布日期: 2025-03-31 12:16:51
在科研与工业场景中,实验数据的可靠性直接影响研究结论或产品质量。数据采集过程...
