
发布日期: 2025-03-31 11:09:01
股市瞬息万变,价格波动往往在几分钟内决定盈亏。对于普通投资者而言,实时盯盘耗...

发布日期: 2025-03-30 14:49:48
在数字化进程加速的当下,网络性能的稳定性直接影响用户体验。传统测速工具往往受...

发布日期: 2025-04-12 11:53:40
在现代软件开发与数据交互场景中,JSON和XML作为两种主流的数据交换格式,常因不同系...

发布日期: 2025-03-20 16:13:38
随着数据规模指数级增长,传统单机处理CSV文件的方式逐渐暴露瓶颈。某金融公司最近...

发布日期: 2025-03-30 19:45:25
打开气象研究员的电脑,总能看到满屏的温度曲线和色块图表,这些二维数据如何突破...
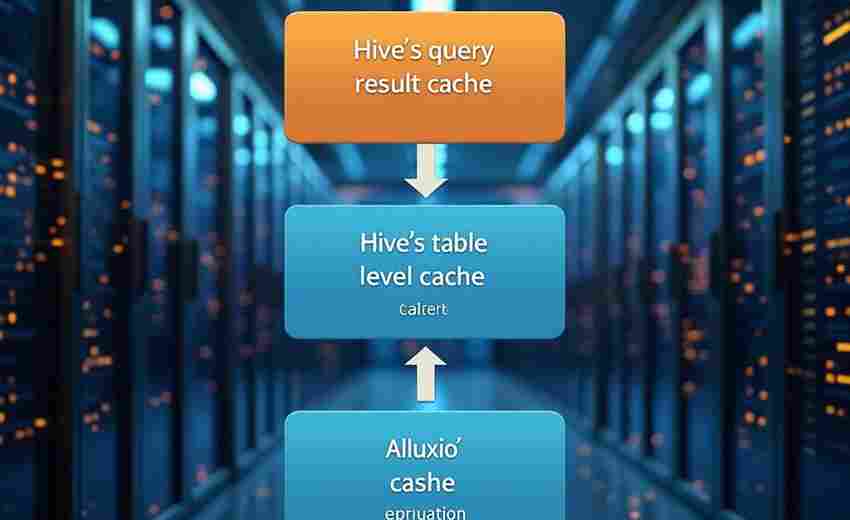
发布日期: 2025-04-07 13:26:14
网络通信开发领域存在一个经典练手项目:基于Socket和多线程的TCP聊天室。这个不足...

发布日期: 2025-04-13 15:28:14
在数据驱动的技术场景中,高效获取网页内容成为开发者必备技能。Python生态中的Req...

发布日期: 2025-04-19 15:23:01
在数字化运维与安全分析领域,日志数据是反映系统运行状态的"黑匣子",但海量日志...

发布日期: 2025-03-22 12:05:17
日常开发中处理复杂数据结构时,控制台打印的混乱格式常让人头疼。Python标准库中的...

发布日期: 2025-04-08 15:50:29
数据格式转换一直是企业信息化管理中的高频需求。在财务报表生成、供应链信息同步...

发布日期: 2025-04-10 10:33:01
当代人的睡眠问题正成为健康领域的隐形杀手。传统睡眠监测设备多聚焦于心率、体动...

发布日期: 2025-04-01 15:53:46
在数据驱动的场景中,快速定位并提取信息是许多开发者和分析师的核心需求。SQL Te...

发布日期: 2025-04-11 14:32:00
局域网即时通讯工具在特定场景下展现出不可替代的实用价值。这类工具不依赖互联网...

发布日期: 2025-03-28 16:29:50
在互联网信息爆炸的时代,数据采集效率直接影响着企业决策和业务迭代速度。面对动...

发布日期: 2025-04-06 14:07:53
在信息爆炸的时代,Reddit作为全球最大的社交新闻聚合平台,每天产生数万条热门讨论...
发布日期: 2025-04-01 13:42:01
在软件质量保障体系中,测试数据的高效生成直接影响测试覆盖率和缺陷发现效率。传...
发布日期: 2025-03-21 10:56:55
在工业生产和实验室环境中,温控设备运行数据的有效利用直接影响着设备管理效率。...
发布日期: 2025-03-27 12:45:14
在数据驱动的时代,天气数据的获取对于气象研究、商业决策甚至日常生活规划都至关...

发布日期: 2025-04-12 15:35:03
深夜台灯下翻开电子书的读者,通勤路上戴着耳机的上班族,渴望获取知识却视力受限...

发布日期: 2025-04-14 17:03:36
专利无效宣告程序直接影响专利权的法律效力,其数据价值长期被行业忽视。近年来,...

发布日期: 2025-04-09 16:53:37
网络运维工作中,端口扫描是摸清资产底数的常规操作。传统单线程扫描器面对C段地址...
发布日期: 2025-04-04 17:04:30
数据可视化领域存在一个有趣的现象:90%的分析师仍在使用静态图表工具。当鼠标滑过...

发布日期: 2025-03-26 16:49:06
在数据库密集型应用场景中,查询性能直接影响着系统响应速度和用户体验。基于PyO...

发布日期: 2025-04-21 17:00:00
数据安全与格式兼容性已成为现代数据处理的核心痛点。面对CSV与JSON之间的频繁转换需...
发布日期: 2025-04-03 15:48:52
股票基金数据定时抓取与可视化工具,本质上是一个面向金融市场的数字化解决方案。...

发布日期: 2025-03-31 17:30:21
在企业数字化转型浪潮下,数据可视化工具已成为职场人士的刚需。面对海量的CSV/XL...

发布日期: 2025-04-04 12:23:11
在数据处理领域,CSV与Excel文件的双向转换是高频刚需。传统转换工具往往仅完成基础...

发布日期: 2025-04-09 18:44:14
在数据爆炸的时代,电脑里堆积着成千上万的文件。某次整理工作文档时,偶然发现同...
发布日期: 2025-04-01 11:36:26
数据表内容可视化图表生成器作为现代数据分析领域的实用工具,正逐步成为企业及个...

发布日期: 2025-03-22 10:40:49
在阳台上种死第三盆薄荷后,老张终于意识到种花种草不能只靠"感觉"。浇水是否过量...

发布日期: 2025-04-02 12:27:02
现代人对于天气信息的依赖远超想象。早晨出门是否需要带伞,出差前查看目的地温度...

发布日期: 2025-04-10 11:44:19
凌晨三点的办公室,屏幕上闪烁的SQL报错信息让张明揉了揉发酸的眼睛。这是他本周第...

发布日期: 2025-04-02 13:59:29
在数据安全领域,文件校验工具长期存在算法单一、验证效率低的痛点。某技术团队近...
发布日期: 2025-03-22 09:00:01
在日常办公场景中,Excel报表的重复性制作常被视为效率瓶颈。财务人员需要反复核对...

发布日期: 2025-03-23 12:07:37
在数据泄露频发的当下,个人隐私与商业机密的安全防护成为刚需。文件加密工具作为...
发布日期: 2025-04-19 15:51:18
日常办公场景中,面对重复性的数据表格制作任务时,手工复制粘贴不仅耗时费力,还...
发布日期: 2025-04-21 10:59:39
实验室日常工作中,文件名混乱常引发数据丢失或重复采集。某课题组曾因误删一份名...

发布日期: 2025-04-20 15:51:36
电子表格已成为现代办公场景中数据管理的核心载体,随着文件版本迭代频率的加速,...

发布日期: 2025-04-21 09:48:19
全球地震活动监测领域近年来迎来技术突破,美国地质调查局(USGS)开发的USGSAPI工具...
发布日期: 2025-03-23 13:56:23
CSV文件自动化测试数据生成工具在软件测试领域正逐渐成为效率提升的突破口。这类工...

发布日期: 2025-04-03 18:18:34
在日常处理视频文件时,时长和分辨率是最常被关注的参数。无论是剪辑素材前的筛选...
发布日期: 2025-03-26 18:08:20
在工业自动化、物联网及智能设备广泛应用的今天,传感器数据的准确性与可靠性直接...

发布日期: 2025-04-18 14:19:12
金融市场的高频交易与海量数据环境下,异常值检测逐渐成为量化投资与风险管理的关...
发布日期: 2025-04-03 12:28:58
电子书制作领域近日出现了一款名为EPUB Navigator的专业工具,其独特的XHTML文件关系图谱...

发布日期: 2025-03-30 19:17:07
在数据安全事件调查中,超过37%的泄密行为与未经授权的USB设备使用直接相关。传统审...
发布日期: 2025-04-07 16:32:24
数据实验室的灯光彻夜未明,研究员王宇盯着屏幕上的数据矩阵,缺失值形成的空白区...

发布日期: 2025-04-14 13:37:01
城市大气污染监测领域存在一个普遍痛点:传统空气质量监测系统产生的非结构化数据...

发布日期: 2025-04-04 14:03:01
Excel到PowerPoint图表生成工具:让数据汇报高效升级 在企业汇报、学术研究或市场分析场...

发布日期: 2025-03-28 19:49:07
数据库连接池作为现代应用系统的关键组件,其稳定性直接影响业务连续性。某科技团...

发布日期: 2025-03-29 16:47:14
在数据驱动的互联网时代,网络爬虫已成为企业获取公开信息的重要技术手段。爬虫运...

发布日期: 2025-04-05 16:17:51
在数据清洗领域,重复记录的处理始终是高频需求。某款名为CSVDeduplicator的开源工具最...

发布日期: 2025-03-21 13:51:22
知乎作为国内头部知识分享平台,汇聚了海量用户生成内容。如何高效提取并分析这些...

发布日期: 2025-03-27 18:37:47
互联网时代的数据洪流中,如何快速获取有效信息成为技术人员的必修课。一款优秀的...

发布日期: 2025-03-30 13:59:55
深夜整理音乐收藏时,突然发现某张专辑的发行年份标注错误,歌手名字拼写混乱,这...

发布日期: 2025-03-23 12:29:22
在数字内容爆炸式增长的今天,个人创作者与企业用户普遍面临视频文件管理难题。某...

发布日期: 2025-04-20 13:00:41
实验室的灯光下,研究员王宇盯着电脑屏幕上的数据皱起眉头。他刚收到美国合作方发...

发布日期: 2025-03-24 13:19:34
在数据驱动的现代工作场景中,自动化生成标准化报告的需求持续增长。基于Python生态...

发布日期: 2025-04-12 10:10:22
纸质书到数字阅读的转型浪潮中,EPUB格式逐渐成为电子出版领域的通用标准。面对创作...

发布日期: 2025-03-22 13:34:01
在数据库开发领域,超过68%的中小型项目选择SQLite作为存储方案。这个轻量级数据库虽...

发布日期: 2025-04-09 16:57:01
环保数据研究领域近期出现了一款名为"AirVision Pro"的空气质量分析工具,该程序依托环...
