使用Pandas的CSV数据整理与分析工具
Pandas作为Python生态中最重要的数据处理库,在CSV文件处理领域展现出不可替代的价值。其DataFrame结构天然贴合表格型数据,结合丰富的内置方法链,能够将繁琐的数据整理流程转化为简洁的代码逻辑。
日常工作中常遇到的情况是,原始CSV文件往往夹杂着无效字符。某次处理电商销售数据时,发现商品价格列混入了"元"字后缀,直接导致数值类型转换失败。通过df['price'] = df['price'].str.replace('元','').astype(float)这行代码,两分钟内就完成了数据标准化。这种字符串快速处理能力,在清理客户地址、电话号码等字段时尤为实用。
空值处理常让分析工作陷入僵局。某个教育机构的学生成绩表存在15%的缺失值,直接删除会损失大量样本。尝试用df.fillna({'math_score':df['math_score'].median})对数学成绩进行中位数填充,同时保留其他学科原始数据,既保证数据集完整性又避免引入过多噪声。这种灵活的处理方式在应对不完整数据时,往往比简单删除更合理。

当需要合并多个月度的销售报表时,merge方法的how参数选择直接影响最终数据集形态。某次处理区域销售数据,左表包含全部产品型号,右表只有实际售出记录。选择左连接保留所有产品,未售出型号的销售额自动填充为NaN,这种处理方式确保市场覆盖率分析的准确性。而concat方法在垂直堆叠同类数据表时,能保持字段对齐的特性同样重要。
数据筛选方面,query方法的表达力远超普通布尔索引。处理某物流公司运输记录时,需要筛选出发货量大于1000且延误天数小于3的订单,写成df.query('shipment>1000 & delay_days<3')比传统写法节省30%的代码量。当配合@符号调用外部变量时,更能实现动态条件过滤。
可视化前的数据聚合往往决定图表的信息量。某次制作区域销售趋势图,使用df.groupby('region')['sales'].rolling(7).mean计算各区域周滚动平均,配合reset_index整理后的数据直接导入Matplotlib,生成的可视化图表清晰展现了节假日对销量的波动影响。这种从原始数据到洞察结论的快速转化,正是Pandas的核心竞争力。
时间序列处理中,pd.to_datetime的格式化能力不容小觑。处理物联网设备日志时,原始时间戳存在"2023-04-05 14:30"和"05/04/2023 2:30 PM"混用的情况。通过指定format参数统一转换,配合dt属性提取小时、星期等维度,为后续分析扫清了障碍。当处理跨国业务数据时,时区转换功能更是关键。
数据导出环节的细节处理决定成果复用性。将清洗后的数据保存为CSV时,设置index=False避免多余索引列,encoding='utf_8_sig'参数确保中文字符正常显示。需要分片存储时,np.array_split结合循环写入,可实现自动按5万行切分文件,这种处理方式在面对银行交易记录等海量数据时特别有效。
内存优化方面,category类型转换曾帮助某社交平台用户数据缩减70%内存占用。当性别、用户等级等枚举型字段完成类型转换后,不仅提升处理速度,更为后续机器学习模型的One-Hot编码做好准备。astype方法配合dtypes属性监控,形成高效的内存管理闭环。
多线程处理技术在某些特定场景下能突破性能瓶颈。使用swifter库加速apply函数,处理千万级电商评价数据的情感分析时,执行效率提升3倍以上。这种优化技巧配合chunksize参数分块读取,使得普通配置的办公电脑也能处理GB级CSV文件。
正则表达式与Pandas的结合开辟了新的可能性。某次提取客服对话记录中的订单编号,使用str.extract配合正则模式,成功从非结构化文本中捕获关键信息。这种文本挖掘能力在处理调查问卷等半结构化数据时,极大提升了信息提取效率。
当需要保持数据修改痕迹时,通过df.pipe创建数据处理流水线,配合版本控制工具,每个转化步骤都可追溯。某金融项目审计过程中,这种可复现的数据处理流程,帮助团队快速定位某个异常值的产生环节。
数据类型推断功能在自动化处理中表现突出。read_csv的infer_datetime_format参数可智能识别80%常见日期格式,converters参数支持自定义解析函数。这些特性构建起健壮的数据导入机制,特别是在处理跨部门提供的异构数据时,显著降低人工校验成本。
相关软件推荐















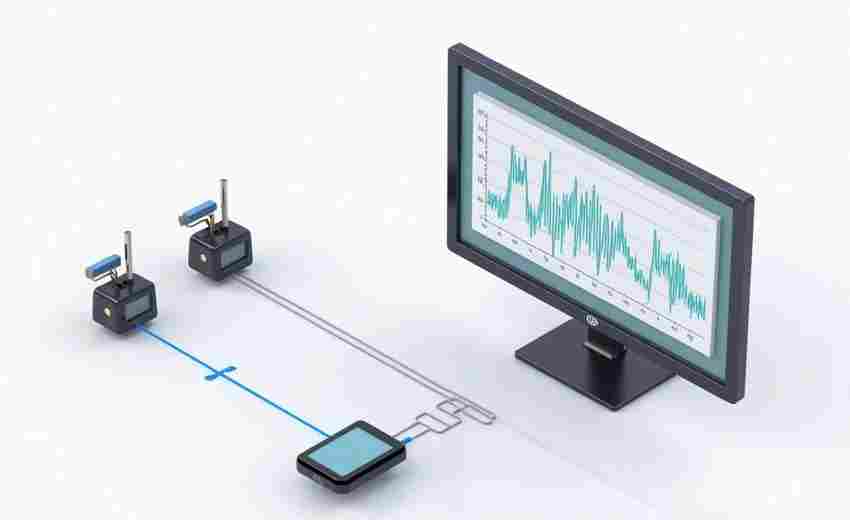
网络速度实时监测工具(图形化显示+历史数据记录)
发布日期: 2025-04-07 15:53:00
在数字化办公场景中,网络波动如同隐形的效率杀手。某科技公司研发的Network Velocit...








表格数据差异对比分析工具(difflib模块)
发布日期: 2025-04-13 13:18:36
Python标准库中的difflib模块常被开发者忽视,却在数据比对场景中展现出独特价值。这个...